AnChain.ai: The use of trading bots leads to great financial losses compared to the “real” trading
By training the AnChain.ai BD algorithm using real trading data, AnChain.ai plans to reduce the losses to the market and provide solutions for “fair” trades. Reducing the bot activity at cryptocurrency trading platforms will allow the regulators to create a policy framework to protect the users and trading platforms to reduce speculative activity.

The use of trading bots is becoming a routine for investors, day traders, or newbies to the trading market. “Make money while you sleep” seems like a sweet deal. While some bots might be helpful at improving efficiency, others might be harmful to both users and the service providers, and moreover, the bot is losing users’ money and thus skew the market data which is hard to analyze.
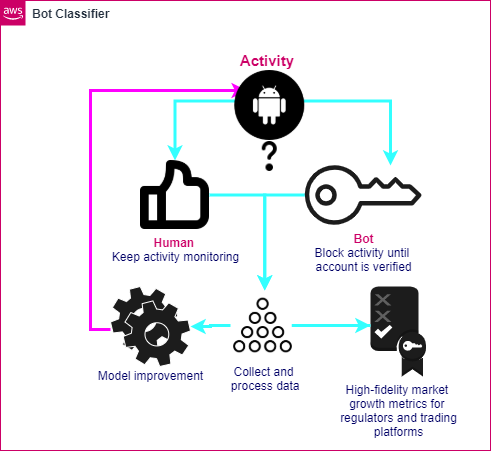
AnChain.ai BD is an AI cryptocurrency bot detection system for trading platforms to identify bot and human activity. AnChain.ai BD can accurately identify bot activity and suspend the suspicious activity, provide the analyzed data reports to the regulatory bodies, and protect the market players from harm caused by bots. After analyzing the data of trading platform users, on average bots losing 77 times more money per user than human traders!
For the past 3 months, AnChain.Ai and the student group from UC Berkeley have been working on data analysis and machine learning algorithm development.
After diving into the data, it became apparent that many Bots were losing money overall on their betting patterns. Bots actually lost more money than Human users on average!

We uncovered a few reasons for this phenomenon:
- Bots were utilizing an approach similar to SEO (Search Engine Optimization). Bots were not concerned with losing money, but rather just inflating the total valuation of the platform. Investors holding the DApp native currency (Endless Token with regards to our data) would use bots to artificially increase transaction volume metrics, inflating the value of the native currency they are holding.
- Bots which were losing money are sending ‘Dividends’ to a single user controlling numerous bots. Bots can add an account listed as a ‘reference’ as a part of their bets, sending a small dividend to a specified user with each bet. Even though individual bots may be losing money, the sum of all the dividends produced from the bots still nets the central account user a positive profit.
- Some Bots were created with the intent of spamming ads for competing blockchain applications. Their bets were accompanied by spam messages encouraging fellow users to go toward other decentralized betting platforms.
The developed algorithm will be integrated into the trading platform to allow constant monitoring of user activity. In this case, if the bot-like activity is detected, the user account will be frozen until further verification. The results of this cross-validation process will allow us to constantly improve the model accuracy and adapt to new bot behavior, at the same time the data analyzed will be transferred to regulators and customers.
To simulate a real blockchain transaction, we operated on an unlabeled dataset. As a result, our first step was to get labels for model training purposes. In order to gain more accurate models, we built a productivity tool that enabled us to manually label data based on visualization of the user’s weekly activities.

Everytime we label an user, the system will automatically refresh and show a heatmap of the user’s activities in different hours of 7 days in a week. From this plot, each team member could systematically label every user. We could also skip some users to be undetermined if we are not sure by using the ‘BACKTRACK’ button. After we gathered all labels from every team member, we did a majority vote to come up with about 600 trustworthy labels. Together with the 1000 bots with obvious patterns we filtered out, we got a dataset with about 1600 trustworthy labels. To ensure a balance of the dataset, we also did down-sampling and data-augmentation. Finally, with bootstrapping, we got a dataset with 30% human labels, 30% bots, and 40% obvious bots. Then we fitted three models with the dataset we got, which are Random Forest, Perceptron, and Logistic Regression. Our Logistic Regression performed the best among all and reached a high validation accuracy of 97.14%.
Supported by: AnChain.ai
The project contributed by: Alan Chen, Wish He, Nidhi Kakulawaram, Griffin Baum, Dinara Ermakova
For more information, visit our github page or contact Alan Chen at shichuchen0114@berkeley.edu