Smart Compose for Medical Applications
If you are a doctor or clinician, besides meeting with patients and giving out diagnosis/treatment, a large part of your daily job probably involves writing patient examination reports, which are translated to medical codes and sent to insurance companies to determine the amount of money they have to pay you. In fact, doctors on average spend about twice as much time filling out paperwork as seeing patients. Moreover, about thirty percent of the medical coding contains errors, translating to as much as $210B lost and delayed revenue yearly.
Recognizing the room for improved efficiency and accuracy, as well as strongly believing that the doctors deserve to be paid for the medical care they provide, a group of UC Berkeley students set out to develop better technologies to automate the paperwork process. More specifically, the team envisioned to create a predictive healthcare analytics model that would act as a “medical version of Grammarly”.
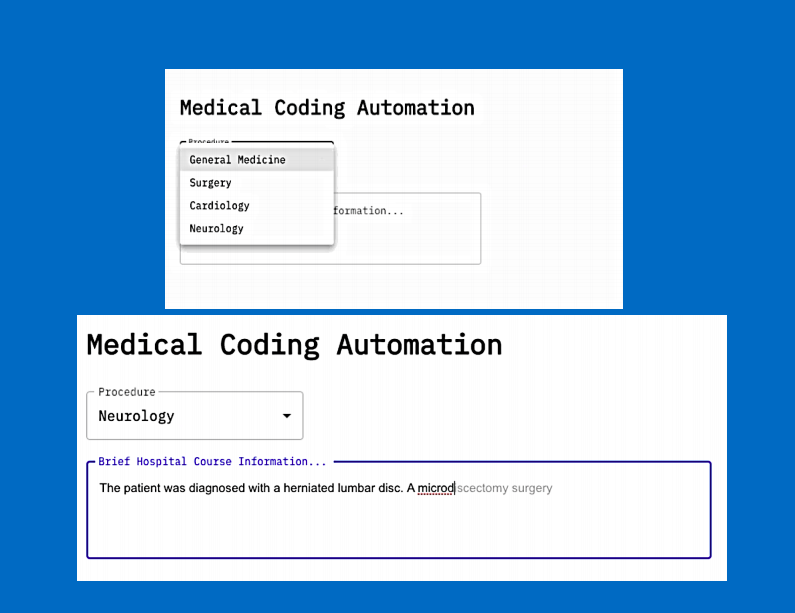
Using over two million rows of real-life medical data from the MIT MIMIC-III database and employing the GPT-2 language model, the team produced a system that can autocomplete the doctors’ input within the Brief Hospital Course Information section of the medical reports based on the selected procedure type (e.g. neurology). Some key areas of future improvement include improving the speed of the model, training the model on larger datasets, and increasing UI simplicity. Despite the limitations of the current model, the team nonetheless was able to generate some valuable insights and produced a meaningful product that demonstrated great potential benefits to the medical industry.
Project by: George Hertlein, Sophie Pealat, David Scanlan, Olivia Zhang