Optimizing Hyperparameter Tuning for Quick and Efficient Decision Making
According to Grand View Research, the global Artificial Intelligence (AI) market was valued at over $60 billion in 2020, and it is expected to grow at a compound annual growth rate (CAGR) of over 40% through 2028. While evidence for the rapid growth of AI can be easily found in our daily lives through applications such as self-driving cars, AI-based voice assistants such as Amazon’s Alexa, personalized ads, and more, what is probably less obvious is the astronomical computing power that is required to run these applications. According to an article from MIT Technology Review, the computing power needed to train AI is rising seven times faster than ever before, and computing usage has increased by over 300,000-fold over the last decade. As datasets become larger and algorithms become more complex, the time that it takes to build and train AI models can grow exponentially, consuming precious time and resources in the process. In fields such as healthcare, every minute lost can mean the difference between life and death for patients. As such, a better approach is needed to improve model performance compared to the solutions that exist in the market today.
Among the most time- and resource-intensive steps involved in building an AI model is a process called hyperparameter tuning in which features inherent to a model are tweaked and adjusted to optimize the model’s performance. As it currently stands, a majority of hyperparameter tuning is achieved through brute computational force — that is, models are trained thousands and thousands of times with different hyperparameter configurations to see which set performs the best.
A group of students at the University of California, Berkeley – in conjunction with industry experts from Uber AI – recognized this problem and created an Application Programming Interface (API) that essentially uses machine learning models to improve other machine learning models more quickly and efficiently. In effect, rather than having to power through thousands of model iterations to determine which hyperparameters offer the best performance, the students at UC Berkeley designed an application that could make intelligent hyperparameter recommendations in real time with far fewer trials. They achieved this by using a conditional probability technique known as Bayesian optimization that learns from previous hyperparameter optimization attempts before making another recommendation. The diagram below shows how these students’ application combines Bayesian optimization techniques with a Flask-linked SQL database to produce better hyperparameter configurations for AI and machine learning models in much shorter time scales.
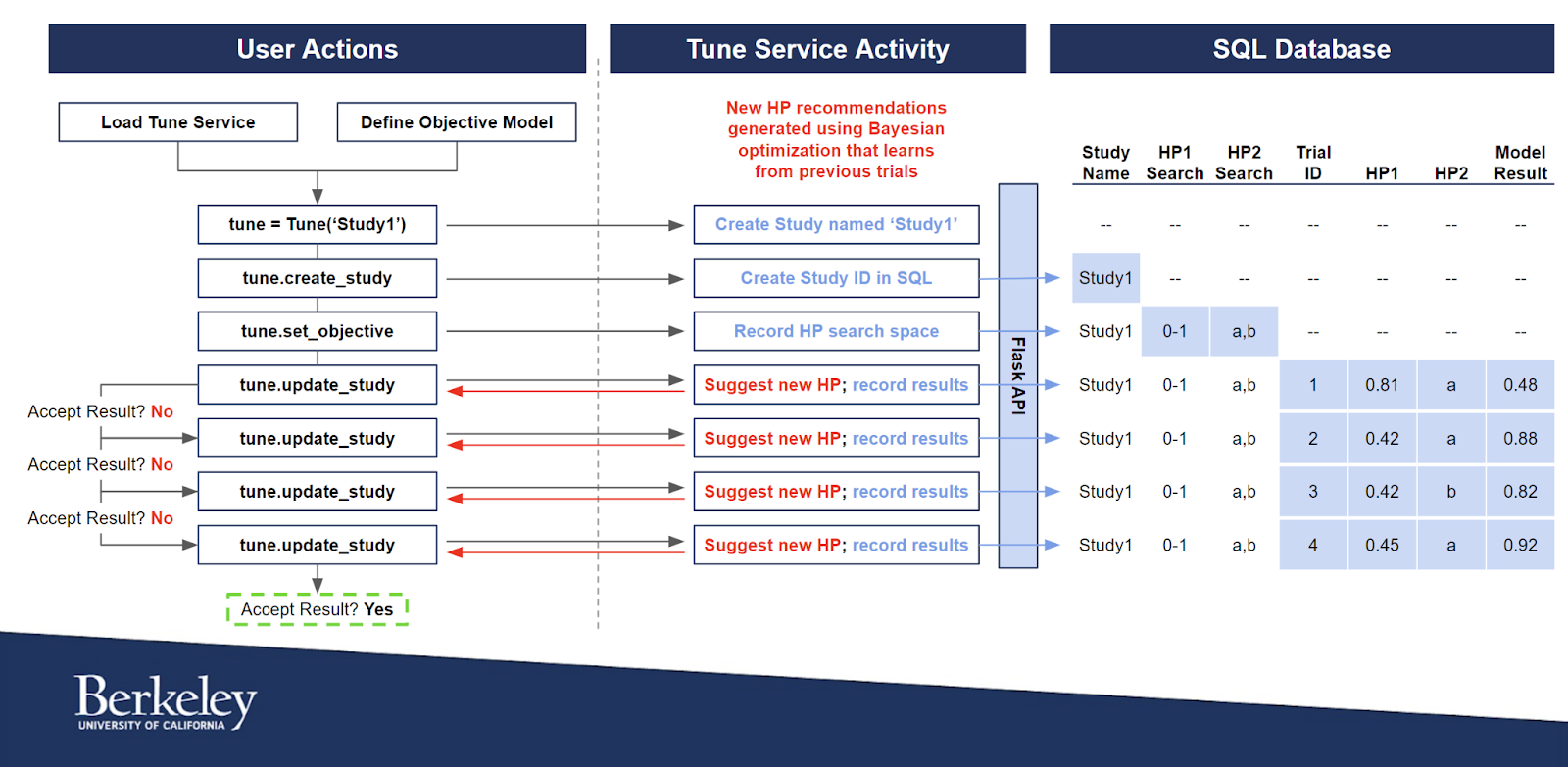
Initial reactions from beta testers of the service have been very positive as there was consensus among the group that this service would significantly improve the throughput of their AI and machine learning workflows, and it could help them make informed decisions more quickly and efficiently when their models do not need precision tuning. Early feedback also indicated areas for improvement that the UC Berkeley team has taken under consideration for future updates to the service. More specifically, early testers of the service wanted to have more transparency into the back-end computations that produce the hyperparameter recommendations so that they could better trust and better understand the outputs they receive. In addition, most beta testers indicated a desire for more visualization tools and dashboard metrics to make it easier to extract study-level insights from their experiments. The UC Berkeley team hopes to roll out features that address these comments in the next iteration of their hyperparameter tuning service.
Public Code Repo: https://github.com/21JC/Team-2-hyperparameter-search
Project By: Viviana Michel, Ashwat Chidambaram, Deepak Ragu, Jiayang Cheng, Yuhan Cheng, Winston Goan
Industry Mentor: Michael Mui